
Introduction
Recently I was reading Data Science from Scratch by Joel Grus. One of Grus’ prerequisites for doing data science is linear algebra. I took a linear algebra course as a freshman but I didn’t do particularly well in it and what little I learned I’ve long since forgotten. So I’ve decided to brush up on my linear algebra by working through a textbook called Linear Algebra by Jim Hefferon, a free online text book recommended by Grus.
In the fifth and final chapter of Linear Algebra the author’s program is to come up with a kind of normal form of matrices that would become an equivalence class for matrices. The chapter starts by introducing the notion of matrix similarity. If two matrices are similar then they essentially are the same transformation, just in different bases.
The normal form the chapter builds to is the Jordan normal form. There are matrices that are diagonalizable and for these matrices a diagonal matrix is the normal form (more on this later). But not all matrices are diagonalizable. Some are nilpotent. A nilpotent matrix is one that when applied to itself multiple times eventually becomes the zero matrix. The canonical form of nilpotent matrices is all zeros and some ones on the sub-diagonal. Jordan normal form essentially combines these two canonical forms to create a canonical form that can represent any matrix.
That’s about all I want to say about Jordan normal form. Here I’ll be focusing on diagonalizability and how to compute eigenvalues and eigenvectors.
Diagonalizable matrices
I introduced matrix similarity by saying that similar matrices represent the same transformation just in different bases. More formally, two matrices, 



A diagonal matrix is defined as a matrix that is all 0’s except for non-zero entries on the diagonal. A matrix 
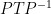
Let’s think a little bit about what a diagonal matrix represents. Let’s say we have a diagonal matrix 

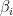

Let’s look at an example. Let T be the following diagonal 2×2 matrix with the natural basis:
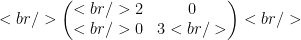
So for 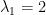
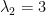
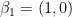

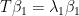
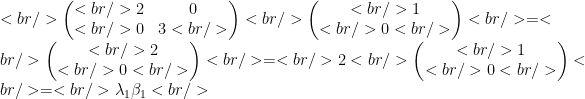
And likewise for 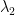

For a diagonal matrix, we’ll call the
Computing Eigenvalues and Eigenvectors
So how do we find eigenvalues? What we’ll do is solve for 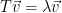
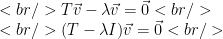




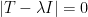
Let’s look at an example. Let

Then
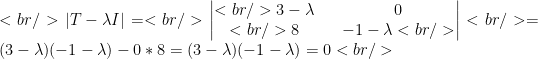
This equation has two solutions, 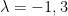
For each eigenvalue we can find a corresponding set of eigenvectors. Let’s start with the eigenvalue -1. We want to find vectors for which 

This becomes the following set of equations:
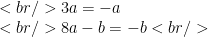
The only solution for the first equation is 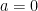
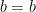
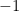
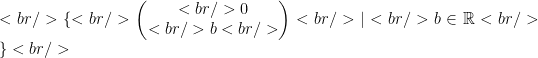
This last is called an eigenspace. We can use any non-zero vector from this space to be an eigenvector, for example if we want to get a basis vector.
Similarly, plugging in the eigenvalue 3 yields
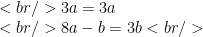
The first equation has an infinite number of solutions. The second equation reduces to 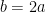
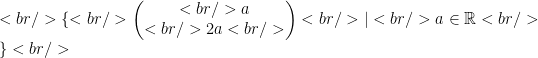
So the diagonal representation of

We can choose two eigenvectors, corresponding in order with the eigenvalues in the above matrix, to make up the basis:

Now that we can compute eigenvalues we can easily determine if a matrix is diagonalizable: a matrix of dimension n is diagonalizable if it has n distinct eigenvalues because we can use those eigenvalues to make up the diagonal entries of the matrix and the eigenvectors associated with them make up the basis. Let 

Conclusion
Now we can not only determine if a matrix is diagonalizable but also produce the diagonal representation of a matrix and its basis. Why would we want to diagonalize a matrix? For a diagonalizable matrix, the diagonal representation is the easiest to work with. One example of how diagonal matrices are easier to work with is matrix exponentiation. If you have a diagonal matrix 

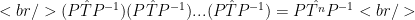
Since computing 
In addition to practical applications can we also develop an intuition about eigenvectors from the preceding discussion? Since a linear transformation applied to an eigenvector doesn’t change its direction, the eigenvectors of a linear transformation can be thought as “axes” of the linear transformation. We can see that from how the eigenvectors of a matrix are used to form the basis vectors for the diagonal representation. The associated eigenvalues can be thought of as the amount of “skew” along those axes that the linear transformation imparts to vectors to which it is applied. So in a sense the eigenvectors and eigenvalues describe the action of a linear transformation on vectors to which it is applied, and this description appears to be as succinct as possible.
- Why is a matrix singular if the determinant is 0? Recall that singular matrices do not have a unique solution. One way to determine if a matrix is singular is to reduce it via Gaussian elimination to echelon form. If the result does not have leading coefficients for each row then it will not have a unique solution. But if it is missing a leading coefficient in one row then it must have a zero on that diagonal entry. One way to compute a determinant is to reduce a matrix to echelon form and then take the product of the diagonal entries. So the determinant will be 0 only if there is a 0 on the diagonal which happens when there is a missing leading coefficient. ↩