It’s pretty easy to create a web component with Vue.js and then consume that web component in a Vue.js app. I’m interested in this as a way to plug in custom user interfaces in the Airavata Django Portal, specifically custom experiment input editors. Using web components as the plugin mechanism allows extensions to be written using any or no framework. But to build a proof-of-concept I decided to build the web component using Vue.js
vue-cli makes it easy to create a Web Component build of a Vue.js component. Just run
vue-cli-service build --target wc src/components/MyComponent.vue
This creates a output files in dist/ called my-component.js and my-component.min.js. It also creates a demo.html file that demonstrates how to load and use the web component. To see this in action, let’s create a simple "Hello World" component and then build and load it.
First, install vue-cli. Then run the following (note: the following assumes yarn is installed, but you can use npm instead):
vue create hello-world
cd hello-world
yarn build --target wc src/components/HelloWorld.vue
Now open dist/demo.html in a web browser. On macOS you can do:
open dist/demo.html
You should see the vue-cli default Vue component boilerplate.
demo.html looks like this:
<meta charset="utf-8">
<title>hello-world demo</title>
<script src="https://unpkg.com/vue"></script>
<script src="./hello-world.js"></script>
<hello-world></hello-world>
This loads Vue.js as a global object and the built web component script. The ./hello-world.js script registers the web component so it is immediately availble for use as shown at the bottom: <hello-world></hello-world>.
So that’s how to build a Vue.js web component and how to load it in a basic web page. But how would you load it in a Vue.js application and integrate it? There are a few things to keep in mind.
vue-cli externalizes the Vue dependency
When you load a Vue.js web component you’ll need to make it available in the global scope, that is, a property of the window object. In your Vue.js app, before you load the web component, you’ll need to do something like:
import Vue from "vue";
if (!window.Vue) {
window.Vue = Vue;
}
Using dynamic imports
You can of course import the web component using a script tag, but I feel like in a Vue.js web component it’s more natural to use the dynamic import function.
const webComponentURL = "https://unpkg.com/..."; // or wherever it lives
import(/* webpackIgnore: true */ webComponentURL);
The /* webpackIgnore: true */ is necessary because otherwise Webpack will try to use the import statement at build time to generated an optimized, code-splitted build.
Vue.config.ignoredElements
When you reference custom elements in Vue.js templates, you need to let Vue.js know to ignore them and not expect them to be Vue.js components. Otherwise, Vue.js will generate a warning because it will appear to it that either the developer mistyped the Vue.js component name or that the component wasn’t registered.
For the Airavata Django Portal, what I’ve done is define a prefix (as a regular expression) that will be ignored ("adpf" stands for Airavata Django Portal Framework):
Vue.config.ignoredElements = [
// Custom input editors that have a
// tag name starting with "adpf-plugin-"
// Vue will ignore and not warn about
/^adpf-plugin-/,
]
Dynamically reference web component in Vue.js template
We’ve seen how to use a web component in a Vue.js template: you just use the tag name, like the demo.html example above. But how would you dynamically reference a web component? You can do that with the special ‘is’ attribute, which the Vue.js special component tag also supports.
<template>
<component is="tagName"/>
</template>
<script>
export default {
//...
data() {
return {
"tagName": "hello-world"
}
}
}
</script>
Handling web component events
Web component events are handled a little differently from Vue.js events. First, with Vue.js events you can emit an event with a value which will be passed as the first argument to event handler (see https://vuejs.org/v2/guide/components.html#Emitting-a-Value-With-an-Event for an example). This doesn’t quite work with web components. Instead, the emitted event will have a detail attribute which is an array of the event values. So instead of expecting the first argument to be the event value, the handler should expect the event object as the first argument and then check its detail attribute for the event value.
webComponentValueChanged: function(e) {
if (e.detail && e.detail.length && e.detail.length > 0) {
this.data = e.detail[0];
}
}
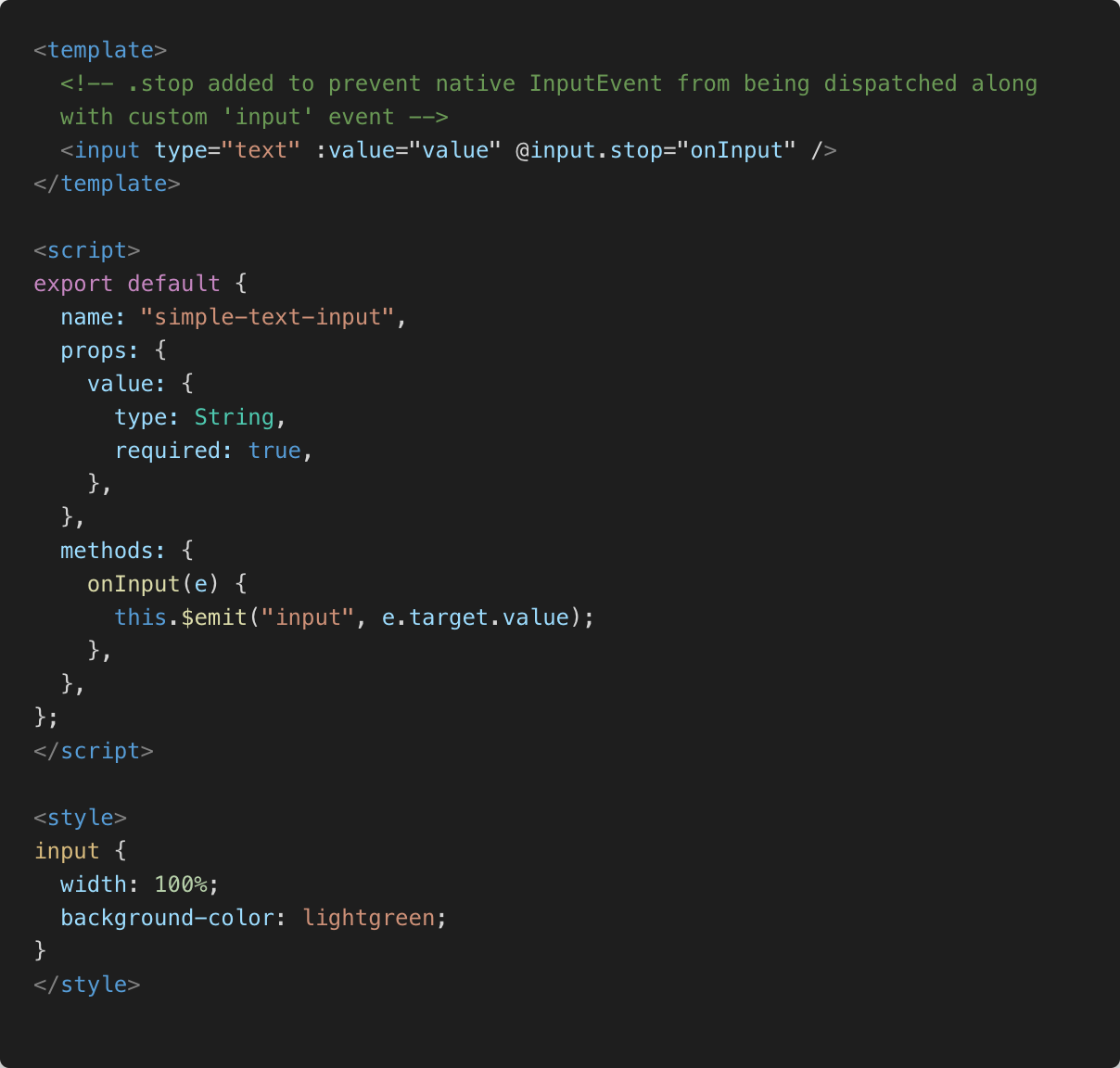
Second, and maybe I’m doing something wrong, but when I have my Vue.js component emit an "input" event, I end up getting two "input" events, one from the Vue.js component and a native "input" event. Perhaps it is more correct to say that when the Vue.js app listens for the "input" event on the web component it ends up getting the native and custom Vue.js "input" events. I was able to prevent the native "input" event with the .stop modifier.
<template>
<!-- .stop added to prevent native InputEvent
from being dispatched along
with custom 'input' event -->
<input type="text" :value="value"
@input.stop="onInput" />
</template>
<script>
export default {
name: "simple-text-input",
// ...
methods: {
onInput(e) {
this.$emit("input", e.target.value);
},
},
};
</script>
Still to do
You can see the code for the web component here: https://github.com/machristie/simple-text-input/blob/master/src/components/SimpleTextInput.vue. Here is the commit for integrating this into the Airavata Django Portal: https://github.com/apache/airavata-django-portal/commit/62e5d606e53f61207e094289607c48e747604bc3
This is a pretty basic proof-of-concept. Things I still want to do:
- Verify the web component can be published to and loaded from a CDN or some other public registry, for example, https://unpkg.com.
- Integrate validation by using the InputEditorMixin. (note: this is Vue.js specific but similar mixins or utilities could be developed for other frameworks.) This mixin automatically runs validation, but the custom input editor could augment this with any custom validation as required. The way we’ve designed the input editors is that the input editor components own the validation of the values, however, most of the validation is metadata driven and not usually implemented in the input editor component.
- Unify some code in the InputEditorContainer. Essentially, as much as possible I don’t want to have two code paths, one for internal Vue components and one for web components, although as pointed out above, event handling is a little different between the two.
- Create a higher level component to load the web components. This higher level component would use
window.customElement.get(tagName)to see if the component is already loaded. - This is more Airavata Django Portal specific, but some input editors need to generate and/or upload an input file. I need to think about how to provide an API that web components can use to easily upload files. File input editors need to register the uploaded file and get back an identifier (called a data product URI) that is then returned as the value (as opposed to string input editors which need to edit the string value and just return the same).